

The global market for data collection and labeling is experiencing explosive growth, expanding from a baseline of $2.22 billion in 2022 to an estimated $17.10 billion by 2030. This upward trajectory is primarily driven by the escalating demand for high-quality, domain-specific training data to fuel advanced machine learning and generative AI models. It highlights a critical industry shift from man
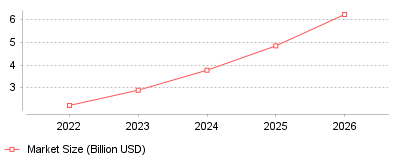
| Year | Market Size (Billion USD) |
|---|---|
| 2022 | 2.22 |
| 2023 | 2.89 |
| 2024 | 3.77 |
| 2025 | 4.84 |
| 2026 | 6.22 |
The data illustrates a rapid, sustained increase in the valuation and adoption of data collection and annotation services, expanding at a massive compound annual growth rate of over 28 percent [1]. It demonstrates how data annotation has evolved from a low-cost, manual outsourcing operation into a strategic, multi-billion-dollar infrastructure capability essential for training complex algorithms like Large Language Models and computer vision systems [2].
On a micro level, this trend signifies that companies building AI must now invest heavily in premium, domain-specific labeling platforms rather than relying solely on cheap, generalized crowd-work. Providers of data labeling software are increasingly integrating semi-supervised workflows, AI-assisted pre-labeling, and synthetic data generation to meet the accuracy demands of specialized fields like healthcare diagnostics and autonomous driving [3]. On a macro level, the entire artificial intelligence supply chain is being re-architected to prioritize "ground-truth" data quality over sheer volume, creating a highly lucrative sub-industry dedicated entirely to RLHF and ethical model alignment [4]. Furthermore, this systemic shift is democratizing AI development, as pay-as-you-go cloud labeling tools and automated dashboards lower entry barriers for small and medium-sized enterprises looking to deploy their own localized machine learning solutions [2].
High-quality labeled data acts as the foundational fuel for modern artificial intelligence; without it, models suffer from severe hallucinations, logical biases, and overall performance degradation. As strict AI governance laws, such as the EU AI Act, begin to demand rigorous, auditable proof of training data provenance and privacy compliance, robust annotation platforms transition from a luxury to a strict legal necessity [2]. Ultimately, the pivot towards highly intelligent data labeling tools ensures that AI systems deployed in high-stakes environments operate safely, precisely, and ethically aligned with intended human values [4].
The primary catalyst for this boom is the unexpected mainstream explosion of generative AI technologies, which rely intensely on human feedback loops to behave safely and follow complex instructions accurately [4]. As core algorithmic architectures become more standardized and openly available, competitive differentiation has aggressively shifted toward the proprietary, highly curated datasets used to train these models. Additionally, the inherent scalability limits and mounting ethical concerns surrounding low-wage human click-farms have forced the industry to innovate rapidly, pushing immense venture capital into startups building scalable, automated labeling engines [5]. Speculatively, the soaring hourly costs of subject-matter experts—such as licensed doctors and lawyers needed for advanced annotations—has accelerated the urgent demand to build smart software that can dramatically amplify a single expert's labeling output.
The data labeling and annotation tools market is undergoing a fundamental transformation, driven entirely by the insatiable need for accurate, specialized data in the rapidly moving generative AI era. What was once considered a rudimentary, manual operational task has firmly emerged as a sophisticated, multi-billion dollar pillar of global technology development. The prominent takeaway is that future artificial intelligence breakthroughs will depend just as much on the advancement of automated, high-fidelity data labeling infrastructure as they will on raw computational power.
Data preparation consumes 80% of artificial intelligence project time [1]. Engineering teams spend weeks converting raw information into structured formats before algorithm training begins. This labor requirement generated a $1.48 billion data collection market in 2024, which Straits Research projects will reach $10.07 billion by 2033 [2]. Other analyst firms forecast steeper adoption curves. Mordor Intelligence expects annotation expenditures to hit $19.9 billion by 2030, representing a 25% compound annual growth rate [1]. Grand View Research tracks similar momentum, predicting the training dataset sector will grow from $2.6 billion in 2024 to $8.6 billion by 2030 [3].
Corporations invest heavily in these foundational layers because algorithmic accuracy depends entirely on initial inputs. Software developers cannot bypass manual taxonomy configuration without degrading output reliability. This structural dependency forces technology companies to purchase specialized software licenses or hire external service providers. The resulting vendor ecosystem contains both independent platform operators and managed service companies that supply human workers.
Organizations deploy these applications across multiple departments to classify text, identify image boundaries, and transcribe audio files. Developers use the resulting outputs to teach systems how to recognize patterns. Demand for these specific outputs accelerates whenever new hardware capabilities enter consumer markets. Market sizing models fluctuate based on how analyst firms categorize automated platforms versus managed service contracts, but total expenditure rises consistently across all major reporting methodologies.
Innodata reported $251.7 million in 2025 revenue, representing a 48% increase from their 2024 results [4]. The company generated $220.8 million of that total through its Digital Data Solutions segment, which provides model preparation services to technology enterprises [5]. Adjusted EBITDA reached $57.9 million for the year, up from $34.6 million in 2024 [4]. Leadership anticipates subsequent revenue growth of 35% in 2026 [6].
This financial expansion relies on narrow customer bases. During the 2024 fiscal year, Innodata derived 48% of its total revenue from a single client [7]. Another customer accounted for 10% of total revenue in 2023 [8]. Client concentration introduces operational risks for software vendors. Contract cancellations or internal strategy shifts at one major technology firm can eliminate half of a vendor's projected income instantly.
Public market investors monitor these earnings reports to gauge broader enterprise adoption trends. When annotation providers exceed consensus estimates, hardware manufacturers often experience parallel stock price increases. Companies mitigate customer concentration risks by launching specific defense capabilities. Innodata partnered with Nvidia in 2025 to release a testing platform focused on vulnerability detection [7]. Federal contract acquisitions provide another diversification strategy, leading vendors to establish government-focused subsidiaries.
Autonomous systems require exceptional capital expenditure before commercial deployment begins. Aurora Innovation spent $745 million on research and development during the 2025 fiscal year [9]. This allocation represented a 10.21% increase over their 2024 research budget [10]. The company applies these funds toward cloud computing, hardware prototyping, and data labeling services [9]. Transportation engineers simulate traffic variations and pedestrian behaviors to test vehicle responses against thousands of distinct scenarios.
Hardware installations continue to scale globally. Gartner tracked 137,129 autonomous driving units in 2018; that number reached 745,705 units by 2023 [2]. Statista projects autonomous vehicle sales will hit 58 million units by 2030 [2]. Every radar pulse, LiDAR scan, and video frame must receive precise coordinate tags before navigation algorithms can process environmental stimuli. Errors in this preparation phase lead directly to physical collisions during real-world operations.
Industrial applications extend beyond passenger vehicles. Construction firms deploy visual recognition models to monitor site safety and track heavy equipment. Supervisors rely on annotation platforms designed for contractors to classify architectural drawings and flag structural defects. Drone operators use similar classification systems to inspect infrastructure assets and survey agricultural properties. These physical deployments demand higher precision thresholds than digital software tools because hardware failures threaten human safety.
Generalist crowdsourcing fails model evaluations requiring advanced reasoning. Technology developers require domain experts to rate output quality for specific professional tasks. Handshake AI manages Project Stagecraft, which pays freelancers between $50 and $500 per hour to complete specialized tasks [11]. The initiative employs roughly 4,000 contractors who develop personas and simulate real work across disciplines like commercial flying and animal husbandry [11].
Reinforcement learning from human feedback dictates these escalating labor costs. Engineers present algorithmic outputs to human workers who rank the responses based on accuracy. This process teaches models to prefer helpful answers and reject harmful suggestions. Standard hourly rates range from $14 for general tasks to $40 for basic domain knowledge, but highly credentialed professionals command premium pricing [1]. Platforms like Scale AI and Labelbox assemble dedicated reviewer teams to manage these complex workflows [12].
Scaling this methodology creates severe compute bottlenecks. Grok 4 utilized 10 times more compute resources for reinforcement learning than Grok 3, yielding only minor improvements on reasoning benchmarks [13]. Expanding context windows multiplies the required model invocations per training episode, placing intense pressure on server infrastructure [13]. Researchers attempt to solve this ceiling by developing multi-agent orchestration techniques and integrating chain-of-thought reasoning into the initial training objective.
Engineers deploy weak supervision algorithms to bypass manual tagging processes entirely. A United States bank used Snorkel Flow to automate the review of 10-K financial documents [14]. The implementation team wrote software functions that programmatically generated 70,000 labels per minute [14]. This automated pipeline saved financial analysts 2,000 hours of manual document review time [14]. Creating the production application required exactly six weeks of engineering work.
Precedence Research expects the automated labeling segment to grow at a 33.2% rate between 2025 and 2034 [3]. Teams evaluate AI, automation, and machine learning tools to control rising labor expenses. Instead of asking a worker to draw polygons around vehicle pixels, an algorithm suggests the boundary shape automatically. Human reviewers verify the algorithmic suggestion rather than creating the shape from scratch. This workflow reduces processing time while maintaining output consistency.
Synthetic generation offers another route past human bottlenecks. Software engines create artificial datasets that mimic real world distributions without containing actual user information. This technique protects consumer privacy while providing unlimited training examples. When document formats shift, engineering teams modify their programmatic functions and regenerate the entire dataset within minutes. Manual operations require months to reprocess equivalent file volumes when business rules change.
The European Union Artificial Intelligence Act established strict training requirements across 27 member states. Prohibitions on unacceptable risk practices became legally binding on February 2, 2025 [15]. Noncompliance triggers fines reaching 35 million euros or 7% of global annual turnover, whichever amount is higher [16]. Supplying incorrect information to national competent authorities results in penalties up to 7.5 million euros or 1% of turnover [17]. The extraterritorial reach affects any corporation deploying systems that interact with European residents.
These mandates force companies to document their entire data supply chain. Compliance officers audit data labeling and annotation tools for sourcing traceability. The European Data Protection Board issued a 2024 opinion reinforcing the necessity of privacy workflows during the labeling phase [18]. Administrators must record exactly who labeled specific files, whether they used crowdsourced workers, and what quality assurance procedures governed the project. Inter-annotator agreement metrics prove that companies tested their models for subjective bias.
International frameworks mirror this legislative urgency. China finalized the Measures for Labeling AI-Generated content, which take effect in September 2025 [19]. The Chinese cybersecurity specification sets explicit security standards for annotation processes to prevent model vulnerabilities. In the United States, the Office of Management and Budget published memorandum M-25-21 in April 2025 [19]. The directive requires federal agencies to appoint Chief AI Officers and publish annual use case inventories. These converging international regulations transform dataset preparation from a technical task into a legal liability.
Enterprise departments configure distinct pipelines for specific file formats. Healthcare organizations demand HIPAA-compliant infrastructure to process electronic health records and medical images. Medical platforms require board-certified physicians to verify diagnostic labels, driving per-item costs exponentially higher than retail equivalents. Morgan Stanley reported that healthcare corporations increased their artificial intelligence budget allocations to 10.5% in recent years [2].
Marketing firms analyze consumer sentiment across varied media channels. Campaign managers tracking conversion rates rely on annotation applications for digital marketing agencies to categorize social media interactions. These tools flag toxic content and segment customer reviews into positive or negative categories. Print advertising divisions require distinct annotation systems built for marketing agencies to evaluate brand placement in offline media. Agency directors use the resulting insights to adjust spending allocations before launching national campaigns.
Financial institutions train algorithms to detect fraudulent transactions and assess credit risk. Banking models ingest millions of historical ledger entries to identify anomalous payment patterns. Legal departments process contracts using named entity recognition to extract liability clauses automatically. Each vertical requires specific taxonomic structures and domain expertise. Software vendors adapt their core platforms to serve these isolated industries, creating fragmented niche markets within the broader annotation software category.
By 2026, organizations will abandon 60% of their machine learning projects due to insufficient data readiness [1]. Enterprise leaders underestimate the structural difficulty of transforming raw files into algorithmic inputs. Gartner identified a $12.9 million average annual loss per organization stemming directly from poor data quality [3]. When inaccurate labels enter the training pipeline, the resulting models generate flawed recommendations that disrupt business operations.
Despite these high failure rates, corporate investment accelerates. Cloud artificial intelligence markets will reach $274.54 billion by 2029, representing a 32.37% growth rate from their $67.56 billion valuation in 2024 [20]. Over 60% of enterprise organizations plan to integrate generative models into their standard workflows by 2025 [21]. Amazon Web Services, Microsoft Azure, and Google Cloud Platform control 66% of total cloud infrastructure spending, providing the server capacity required for these massive deployments [20].
Software buyers must balance aggressive integration timelines against strict regulatory compliance. The financial penalties outlined in the European Union legislation eliminate any margin for error in dataset provenance. Executives will increasingly shift capital away from generalist crowdsourcing platforms toward automated weak supervision systems and domain-specific expert networks. The platforms that survive this market transition will offer verifiable audit trails, programmatic taxonomy adjustments, and secure integration with established cloud infrastructure.
The global market for data collection and labeling is experiencing explosive growth, expanding from a baseline of $2.22 billion in 2022 to an estimated $17.10 billion by 2030. This upward trajectory is primarily driven by the escalating demand for high-quality, domain-specific training data to fuel advanced machine learning and generative AI models. It highlights a critical industry shift from man
| Year | Market Size (Billion USD) |
|---|---|
| 2022 | 2.22 |
| 2023 | 2.89 |
| 2024 | 3.77 |
| 2025 | 4.84 |
| 2026 | 6.22 |
The data illustrates a rapid, sustained increase in the valuation and adoption of data collection and annotation services, expanding at a massive compound annual growth rate of over 28 percent [1]. It demonstrates how data annotation has evolved from a low-cost, manual outsourcing operation into a strategic, multi-billion-dollar infrastructure capability essential for training complex algorithms like Large Language Models and computer vision systems [2].
On a micro level, this trend signifies that companies building AI must now invest heavily in premium, domain-specific labeling platforms rather than relying solely on cheap, generalized crowd-work. Providers of data labeling software are increasingly integrating semi-supervised workflows, AI-assisted pre-labeling, and synthetic data generation to meet the accuracy demands of specialized fields like healthcare diagnostics and autonomous driving [3]. On a macro level, the entire artificial intelligence supply chain is being re-architected to prioritize "ground-truth" data quality over sheer volume, creating a highly lucrative sub-industry dedicated entirely to RLHF and ethical model alignment [4]. Furthermore, this systemic shift is democratizing AI development, as pay-as-you-go cloud labeling tools and automated dashboards lower entry barriers for small and medium-sized enterprises looking to deploy their own localized machine learning solutions [2].
High-quality labeled data acts as the foundational fuel for modern artificial intelligence; without it, models suffer from severe hallucinations, logical biases, and overall performance degradation. As strict AI governance laws, such as the EU AI Act, begin to demand rigorous, auditable proof of training data provenance and privacy compliance, robust annotation platforms transition from a luxury to a strict legal necessity [2]. Ultimately, the pivot towards highly intelligent data labeling tools ensures that AI systems deployed in high-stakes environments operate safely, precisely, and ethically aligned with intended human values [4].
The primary catalyst for this boom is the unexpected mainstream explosion of generative AI technologies, which rely intensely on human feedback loops to behave safely and follow complex instructions accurately [4]. As core algorithmic architectures become more standardized and openly available, competitive differentiation has aggressively shifted toward the proprietary, highly curated datasets used to train these models. Additionally, the inherent scalability limits and mounting ethical concerns surrounding low-wage human click-farms have forced the industry to innovate rapidly, pushing immense venture capital into startups building scalable, automated labeling engines [5]. Speculatively, the soaring hourly costs of subject-matter experts—such as licensed doctors and lawyers needed for advanced annotations—has accelerated the urgent demand to build smart software that can dramatically amplify a single expert's labeling output.
The data labeling and annotation tools market is undergoing a fundamental transformation, driven entirely by the insatiable need for accurate, specialized data in the rapidly moving generative AI era. What was once considered a rudimentary, manual operational task has firmly emerged as a sophisticated, multi-billion dollar pillar of global technology development. The prominent takeaway is that future artificial intelligence breakthroughs will depend just as much on the advancement of automated, high-fidelity data labeling infrastructure as they will on raw computational power.