

3..
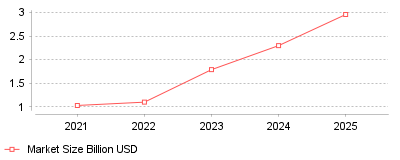
| Year | Market Size Billion USD |
|---|---|
| 2021 | 1.03 |
| 2022 | 1.1 |
| 2023 | 1.79 |
| 2024 | 2.3 |
| 2025 | 2.96 |
The data highlights a massive technological migration in the document scanning sector, where traditional Optical Character Recognition (OCR) is being aggressively replaced by Intelligent Document Processing (IDP). Market research indicates that the global IDP market has experienced continuous, compounding growth, expanding from roughly $1.03 billion in 2021 to a projected $2.96 billion in 2025 [1] [2]. This revenue boom is fueled by a staggering 66% of enterprises actively replacing their outdated legacy OCR systems with modern, AI-driven platforms [3]. Rather than plateauing, this trajectory reveals that 78% of organizations are already operational with AI-powered document technology, marking a definitive end to basic digital scanning and ushering in an era of autonomous data comprehension [4].
On a micro level, this transition means that businesses are no longer satisfied with software that merely extracts raw text from digital images via rigid, template-based constraints. Enterprises now mandate systems that can autonomously understand context, classify unstructured data, process multi-column formats seamlessly, and perform complex validations without any human intervention. On a macro industry level, this paradigm shift is severely disrupting legacy vendors who are burdened with technical debt, while heavily rewarding agile startups and cloud-native platforms that natively embed machine learning and generative AI into their pipelines. It signifies that natural language processing (NLP) and Large Language Models (LLMs) have become the absolute baseline for enterprise workflow automation, completely changing software buyer expectations. Consequently, organizations are experiencing straight-through processing rates that jump from a mere 60% with traditional OCR methodologies to as high as 99% accuracy when applying generative AI to complex edge cases [5].
This trend is critically important because unstructured data—spanning emails, PDFs, complex contracts, and handwritten notes—makes up the vast majority of enterprise information, and unlocking it efficiently drives immense operational savings. As 62% of IDP systems now actively involve external users, the technology has officially moved beyond back-office invoice processing into front-office, customer-facing applications like KYC (Know Your Customer) compliance, loan origination, and patient onboarding [6]. Organizations that stubbornly cling to outdated OCR technologies will inevitably face steep competitive disadvantages, higher operational overhead, and slower decision cycles compared to peers who can instantaneously synthesize actionable insights from millions of documents.
The primary catalyst for this shift is the recent, explosive advancement in the capabilities of Large Language Models (LLMs) and generative AI, which inherently solve the fatal limitations of template-bound OCR systems by introducing zero-shot learning and contextual reasoning. Additionally, the increasing complexity of global regulatory compliance demands higher accuracy, strict data residency, and robust audit trails that traditional software simply cannot provide at an enterprise scale [7]. The permanent shift to remote and hybrid work environments also exposed the fragility of manual, paper-based data entry workflows, forcing an accelerated timeline for comprehensive digital transformation across heavily regulated sectors like BFSI (Banking, Financial Services, and Insurance). Speculatively, as the computing costs required for executing NLP and LLMs have steadily decreased, the financial barrier to entry for highly intelligent data extraction has been lowered, allowing even small and medium-sized enterprises (SMEs) to afford automation tools that were previously reserved for massive conglomerates.
The swift transition from basic Optical Character Recognition to generative AI-driven Intelligent Document Processing marks a permanent evolution in enterprise data management, with the total addressable market projected to exceed $12.35 billion by 2030 [2]. To survive this shift, organizations must audit their current document scanning workflows and aggressively prepare to integrate predictive and generative AI models, or risk immediate operational obsolescence. The prominent takeaway is clear: document processing is no longer simply about digitizing physical text into a computer; it is about deploying AI agents capable of autonomously understanding, reconciling, and actioning enterprise knowledge at unparalleled speed and scale.
Enterprise spending on character recognition reached $12.25 billion in 2024 [1]. Market projections show this category expanding to $51.23 billion by 2033 [1]. The extraction sector generated $2.3 billion in 2024 [2]. Analysts project a 24.7% growth rate through 2034 [2]. Corporate leaders mandate digital initiatives across all departments. Paper records consume expensive commercial space. Metal cabinets slow down information retrieval. Employees lose valuable hours searching for misfiled documents. Transitioning to digital formats solves these operational inefficiencies. Software adoption continues unabated across corporate sectors.
To convert physical paper into digital formats, offices purchase hardware. The scanner market generated $3.7 billion in 2024 [3]. Wireless models accounted for $2.4 billion of this revenue [3]. Network connectivity allows immediate server uploads. Employees bypass desktop computers entirely. They scan paperwork straight into folder structures. This direct routing saves considerable time. Despite wireless growth, offline machines retain a 71% market share [3]. Buyers prefer physical testing before purchasing equipment. Healthcare organizations prefer offline access to maintain strict security. Legal firms require local control over client files. Hybrid models claim 7% market share [4]. Flatbed scanners hold $1.8 billion in market share [3]. Graphic designers require premium flatbeds for color accuracy. Corporate mailrooms use production scanners instead. These machines process 100 pages per minute effortlessly. They detect double feeds using ultrasonic sensors. They adjust image contrast automatically during scanning. They deskew crooked pages before saving files. This preprocessing improves software accuracy significantly. Reduction algorithms clean dark backgrounds. Faded images degrade extraction quality. Clean images ensure accurate extraction.

Historically, extraction programs relied on zonal templates. Administrators drew bounding boxes over document images. Software read text within these specific coordinates. If vendors shifted invoice margins, extraction failed completely. Systems returned blank fields. They returned incorrect strings. This rigidity forced employees to create numerous templates. Maintenance consumed hundreds of labor hours annually. Software updates broke existing templates frequently. Modern platforms abandon zonal coordinates entirely. They use computer vision to analyze layout structures. They apply language models to interpret text. Programs read entire pages at once. They understand semantic relationships between words. They recognize that "Amount Due" equals "Total". They identify tables regardless of border lines. They map nested rows accurately. This flexibility reduces setup time drastically. Software vendor ABBYY recorded a 60% revenue increase during 2023 [5]. Mobile usage grew by 35% [4]. Banking software leads mobile integration. Retailers use mobile scanning for loyalty programs. Onboarding speeds improved by 22% [4]. Fast onboarding reduces client abandonment.
When evaluating cloud architecture, Amazon and Google dominate the extraction market. Testing evaluated 100 documents to compare performance [6]. Google software achieved 95.8% accuracy overall [6]. Amazon software reached 94.2% accuracy [6]. Low-resolution scans present distinct difficulties. Documents below 150 dots per inch lower performance across all platforms. Google scores 81.2% on these files [6]. Amazon scores 76.3% [6]. Table extraction reveals wider performance gaps. Amazon correctly maps 82% of invoice rows [6]. Google processes only 40% of identical rows accurately [6]. Handwriting remains highly problematic. Amazon scores 71.2% on handwritten notes [6]. Google reaches 74.8% [6]. Neither tool replaces human review for cursive text. Pricing models dictate deployment strategies for engineering teams. Processing 200,000 forms costs $10,000 monthly using Amazon servers [6]. Identical volume costs $6,000 on Google servers [6]. This $4,000 differential totals $48,000 annually [6]. Developers connect extraction engines using programming interfaces. Amazon offers a synchronous endpoint. It returns data immediately after submission. It restricts file sizes strictly. It limits page counts per request. Amazon also offers asynchronous endpoints for bulk jobs. Developers submit large files without timeout fears. Servers process these batches in background tasks. They send notifications upon job completion. This method handles large packets effectively. Google structures pricing around 10-page increments. Parsers cost ten cents per block. This pricing model complicates cost estimation. Engineering teams must calculate document lengths before deployment.
Within corporate finance, tax professionals handle complex paperwork daily. Employees review W-2 forms. They process 1099 statements. They transcribe K-1 schedules manually. Manual entry causes frequent mistakes. A misplaced decimal alters tax liabilities significantly. Gartner researchers surveyed 497 professionals in 2024 to understand these challenges [7]. Eighteen percent of accountants make financial errors daily [7]. Thirty-three percent commit weekly mistakes [7]. Fifty-nine percent introduce errors monthly [7]. Workloads increased for 73% of respondents [7]. Economic volatility caused this immense pressure [7]. Errors drain valuable time from client service. Thomson Reuters notes that entry errors top the list of preparation mistakes [8]. Firms deploy specialized transcription systems to automate this workflow. Software performs three-way matching automatically. It compares vendor invoices against purchase orders. It checks delivery receipts for consistency. This verification prevents payment errors entirely. Inefficiency costs companies 20% to 30% of revenue [9]. Automation restores profit margins quickly. Managers redirect saved labor hours toward strategic analysis. Accountants advise clients instead of typing numbers.
During the origination process, lenders face documentation bottlenecks. A typical mortgage requires 300 pages of supporting evidence. Applicants submit bank statements. They provide pay stubs. They upload tax returns. Processing these packets requires manual labor. Fannie Mae surveyed 242 executives across 219 institutions during 2023 [10]. Efficiency motivated 73% of respondents to adopt automation tools [10]. This adoption rate increased from 42% in 2018 [10]. Despite high interest, actual deployment lags. Only 7% of institutions have deployed software fully [10]. Twenty-two percent conduct trial runs [10]. Integration complexity prevents wider adoption. Data security causes hesitation among executives. Lenders require extraction software to parse borrower files safely. Applications identify undisclosed debt automatically. They flag mismatched names instantly. They cross-reference identification numbers. They calculate debt-to-income ratios without human intervention. This preprocessing accelerates loan approvals. Underwriters spend fewer hours typing numbers. They spend more time assessing risk profiles. Fast approvals win clients in housing markets. Borrowers demand quick decisions. Delays cause applicants to seek alternate financing.
Standardized forms create processing challenges for insurance carriers. Industry operations rely heavily on ACORD templates. ACORD 125 represents a commercial application. ACORD 25 serves as a liability certificate. These documents contain checkboxes. They feature handwritten notes. They list coverage limits. Legacy software fails to read cursive text accurately. Modern platforms use context mapping to solve this problem. Agencies provide parsing tools to their adjusters. Software extracts policyholder names. It captures coverage limits. It reads expiration dates. Processing speeds increase dramatically. Infrrd helped an insurance client boost processing speed by 400% using automation [11]. Software parses loss reports. It structures collision details. It extracts witness statements. It maps injury descriptions into database fields. Human operators review flagged exceptions only. This workflow prevents claim denials due to clerical errors. Accurate entry minimizes policy disputes [12]. Faster resolution improves satisfaction scores. Policyholders receive settlement checks sooner.
Because federal law mandates data security, administrators manage patient files carefully. Clinics process lab results daily. They handle referral letters. They intake insurance cards. Medical offices must follow HIPAA regulations strictly. Software encrypts patient information. It generates audit trails for compliance officers. Direct integration reduces filing time. Automation cuts this administrative burden by 50% to 90% [13]. Administrators install digitization software on clinic computers. Software routes documents into health records. It extracts billing codes. It verifies insurance coverage before appointments. It accelerates claims processing with insurance providers. Healthcare organizations increased software adoption by 45% in 2024 [4]. This digitization improved administrative speeds by 30% [4]. In Europe, strict privacy laws dictate technology choices. GDPR compliance drives regional adoption. European businesses account for 22% of market share [1]. Facilities maintain associate agreements with software vendors to guarantee compliance. Violations trigger severe financial penalties. Audits force clinics to prove data provenance. Digital records simplify this reporting requirement.
Out in the field, construction managers face invoicing challenges. Subcontractor billing lacks standardization. Plumbers submit handwritten invoices. Electricians email basic spreadsheets. Lumber yards send printed receipts. Project managers must allocate costs precisely. They assign expenses to specific jobs. They track budget variances. Manual routing causes payment delays. Delayed payments damage vendor relationships. Superintendents use receipt applications to track material costs. Software reads vendor names. It extracts total amounts. It identifies job codes. It ignores layout variations. It exports structured data. This data flows into accounting platforms. Software flags duplicate invoices. It prevents overbilling on material costs. It tracks retention amounts automatically. This immediate visibility prevents project overruns. Construction margins remain notoriously thin. Cost control dictates project profitability. Digital tracking prevents budget leakage.
After processing completes, extraction pipelines require storage. Software generates structured data continuously. Organizations maintain large file repositories to store information. Cloud platforms represented 42% of total deployments in 2024 [4]. IDC predicts cloud revenue will reach $663 billion [14]. Investment in capture applications stems from this storage availability. Servers index text content automatically. Employees search for specific keywords across millions of files. Centralized storage eliminates physical cabinets. It reduces commercial space. Recovery protocols protect against data loss. Redundant servers duplicate information across geographic regions. Access controls prevent unauthorized viewing. Managers assign permissions based on employee roles. Encrypted storage secures intellectual property. Version control tracks document edits over time. Collaboration improves when remote teams access shared files seamlessly.
Looking ahead, software vendors plan to merge text extraction with predictive analytics. Unstructured data constitutes 80% to 90% of newly generated enterprise information [15]. Software will convert this dark data into strategic assets. Algorithms will identify spending patterns. They will predict cash shortages. They will forecast supply disruptions based on invoice delays. Vendors will continue refining language models. Accuracy will approach 100% on handwritten documents. Processing speeds will increase further. Integration costs will decline as programming interfaces become standardized. Enterprises that adopt these tools will reduce operational overhead. They will outpace competitors relying on manual processes. Software will evolve from simple transcription tools into intelligence platforms. The divide between digitized companies and paper-bound firms will widen. Machine learning will dictate competitive advantage across all industries. Data extraction serves as the foundational step for intelligence initiatives.
3..
| Year | Market Size Billion USD |
|---|---|
| 2021 | 1.03 |
| 2022 | 1.1 |
| 2023 | 1.79 |
| 2024 | 2.3 |
| 2025 | 2.96 |
The data highlights a massive technological migration in the document scanning sector, where traditional Optical Character Recognition (OCR) is being aggressively replaced by Intelligent Document Processing (IDP). Market research indicates that the global IDP market has experienced continuous, compounding growth, expanding from roughly $1.03 billion in 2021 to a projected $2.96 billion in 2025 [1] [2]. This revenue boom is fueled by a staggering 66% of enterprises actively replacing their outdated legacy OCR systems with modern, AI-driven platforms [3]. Rather than plateauing, this trajectory reveals that 78% of organizations are already operational with AI-powered document technology, marking a definitive end to basic digital scanning and ushering in an era of autonomous data comprehension [4].
On a micro level, this transition means that businesses are no longer satisfied with software that merely extracts raw text from digital images via rigid, template-based constraints. Enterprises now mandate systems that can autonomously understand context, classify unstructured data, process multi-column formats seamlessly, and perform complex validations without any human intervention. On a macro industry level, this paradigm shift is severely disrupting legacy vendors who are burdened with technical debt, while heavily rewarding agile startups and cloud-native platforms that natively embed machine learning and generative AI into their pipelines. It signifies that natural language processing (NLP) and Large Language Models (LLMs) have become the absolute baseline for enterprise workflow automation, completely changing software buyer expectations. Consequently, organizations are experiencing straight-through processing rates that jump from a mere 60% with traditional OCR methodologies to as high as 99% accuracy when applying generative AI to complex edge cases [5].
This trend is critically important because unstructured data—spanning emails, PDFs, complex contracts, and handwritten notes—makes up the vast majority of enterprise information, and unlocking it efficiently drives immense operational savings. As 62% of IDP systems now actively involve external users, the technology has officially moved beyond back-office invoice processing into front-office, customer-facing applications like KYC (Know Your Customer) compliance, loan origination, and patient onboarding [6]. Organizations that stubbornly cling to outdated OCR technologies will inevitably face steep competitive disadvantages, higher operational overhead, and slower decision cycles compared to peers who can instantaneously synthesize actionable insights from millions of documents.
The primary catalyst for this shift is the recent, explosive advancement in the capabilities of Large Language Models (LLMs) and generative AI, which inherently solve the fatal limitations of template-bound OCR systems by introducing zero-shot learning and contextual reasoning. Additionally, the increasing complexity of global regulatory compliance demands higher accuracy, strict data residency, and robust audit trails that traditional software simply cannot provide at an enterprise scale [7]. The permanent shift to remote and hybrid work environments also exposed the fragility of manual, paper-based data entry workflows, forcing an accelerated timeline for comprehensive digital transformation across heavily regulated sectors like BFSI (Banking, Financial Services, and Insurance). Speculatively, as the computing costs required for executing NLP and LLMs have steadily decreased, the financial barrier to entry for highly intelligent data extraction has been lowered, allowing even small and medium-sized enterprises (SMEs) to afford automation tools that were previously reserved for massive conglomerates.
The swift transition from basic Optical Character Recognition to generative AI-driven Intelligent Document Processing marks a permanent evolution in enterprise data management, with the total addressable market projected to exceed $12.35 billion by 2030 [2]. To survive this shift, organizations must audit their current document scanning workflows and aggressively prepare to integrate predictive and generative AI models, or risk immediate operational obsolescence. The prominent takeaway is clear: document processing is no longer simply about digitizing physical text into a computer; it is about deploying AI agents capable of autonomously understanding, reconciling, and actioning enterprise knowledge at unparalleled speed and scale.