

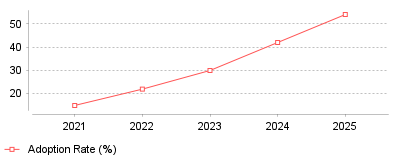
| Year | Adoption Rate (%) |
|---|---|
| 2021 | 15 |
| 2022 | 22 |
| 2023 | 30 |
| 2024 | 42 |
| 2025 | 54 |
The provided data reveals a dramatic acceleration in the enterprise adoption of AI-powered monitoring, escalating from an estimated 15 percent in 2021 to 54 percent by the end of 2025 [1]. This operational shift perfectly mirrors the financial trajectory of the global Artificial Intelligence for IT Operations (AIOps) market, which expanded from approximately 11.5 billion dollars to nearly 19 billion dollars over the same five-year period [2]. What this demonstrates is a decisive industry-wide migration away from fragmented, rule-based alerting systems toward unified, machine-learning-driven observability platforms capable of processing massive volumes of telemetry data in real-time [3].
At a micro level, this transition means that IT and network operations teams are actively consolidating their monitoring tool stacks, significantly reducing the average number of specialized tools per organization from six to around four [4]. Instead of siloing network performance metrics away from application health, engineers are leveraging a great convergence where end-user experience serves as the primary metric and network infrastructure provides the diagnostic context [5]. On a macro industry scale, vendors are aggressively pivoting their portfolios to offer experience intelligence and predictive remediation, with major players acquiring observability startups to build full-stack, end-to-end resilience ecosystems [6]. Furthermore, managed service providers are capitalizing on this trend by bundling AIOps into consumption-based subscriptions, effectively lowering the adoption friction for small and medium-sized enterprises that lack dedicated, round-the-clock site reliability engineering teams [1]. Ultimately, this signifies that traditional network monitoring is evolving into agentic AI execution, where probabilistic machine learning models not only detect anomalies but autonomously reroute traffic and execute self-healing scripts without human intervention.
The financial and operational stakes of maintaining network uptime have never been higher, with network downtime now costing enterprises an average of 5,600 dollars per minute, translating to over 300,000 dollars per hour [7]. Compounding this risk is a severe global workforce crisis; as of 2024, the cybersecurity and IT operations sector faces a staggering shortage of 3.5 million unfilled positions, leaving existing security teams dangerously understaffed and highly susceptible to burnout [8]. Implementing a formal observability and AIOps strategy is vitally important because it directly offsets this human capital deficit by filtering out alert noise, correlating events across complex hybrid architectures, and reducing incident resolution times by up to 50 percent, allowing constrained IT teams to focus on strategic innovation [9].
The exponential proliferation of microservices and cloud-native architectures has generated tenfold more telemetry data than legacy monolithic stacks, fundamentally overwhelming traditional, static threshold-based monitoring tools [3]. Simultaneously, the rapid expansion of edge computing, 5G rollouts, and multi-cloud environments has dissolved the traditional enterprise network perimeter, meaning the vast majority of enterprise traffic now traverses public networks and third-party infrastructures that the enterprise does not directly own [5]. I speculate that the breaking point occurred when alert fatigue reached critical mass; legacy tools produced so many false positive alarms that desensitized on-call engineers began missing genuine, user-impacting incidents. High-profile, costly network outages and increasingly stringent regulatory mandates regarding critical infrastructure visibility likely served as the final catalysts, forcing C-suite executives to aggressively authorize budgets for AI-driven platforms that promise guaranteed service consistency and continuous threat exposure management [10].
The era of fragmented, human-dependent network monitoring is effectively over, rapidly being replaced by an era of autonomous, AI-driven observability that links underlying infrastructure health directly to end-user experience. As digital ecosystems continue to expand in complexity and the global IT skills shortage persists, relying on reactive troubleshooting is a guaranteed path toward catastrophic financial losses and reputational damage. The prominent takeaway for IT and business leaders is that investing in AIOps and unified network observability is no longer merely an operational upgrade, but a foundational requirement for digital resilience and competitive survival in a hybrid-first world.
Gartner projects the total market for observability platforms will reach $14.2 billion by 2028 [1]. Surging infrastructure complexity across hybrid and cloud-native environments drives this capital influx. Narrower network performance monitoring categories demonstrate similar financial momentum. Allied Market Research valued the pure network performance segment at $1.8 billion in 2021, projecting an increase to $4.1 billion by 2031 at an 8.7% compound annual growth rate [2]. Corporate technology budgets reflect a clear pivot from reactive troubleshooting utilities to persistent network visibility platforms that correlate metrics, traces, and application logs.
Corporate buyers face persistent operational friction due to tool sprawl. IT departments historically purchased separate utilities for application monitoring, firewall management, and packet inspection. This fragmented approach forces engineering teams to manually correlate data across multiple dashboards during active system failures. The resulting delays in incident resolution severely impact corporate revenue. Modern vendors differentiate their product lines through unified platforms that reduce mean time to resolution by centralizing data aggregation [1].
Physical environments dictate distinct procurement patterns. Datadog executives noted in their 2024 earnings calls that physical network monitoring products hold the highest appeal for older enterprises managing massive on-premises data centers [3]. Conversely, cloud cost management and database monitoring features attract immediate adoption across all customer profiles. Buyers routinely demand platform consolidation to curb administrative overhead.
Cisco finalized its acquisition of Splunk for $28 billion in early 2024, paying a premium of $157 per share in cash [4]. The transaction represents the largest acquisition in Cisco history. Splunk adds $4 billion in annual recurring revenue to the Cisco balance sheet while bridging a critical architectural gap [5]. Prior to the acquisition, Cisco maintained highly successful point solutions like ThousandEyes for path visualization and AppDynamics for application performance, but these disparate systems lacked a universal data translation layer. Splunk functions as that central data substrate.
Competitors immediately adjusted their market strategies to capture potential customer churn. Forrester principal analyst Allie Mellen observed that the acquisition secures Cisco as a dominant force in security information and event management [4]. Mellen also warned that enterprise users might expand their deployments of Microsoft Sentinel as a defensive hedge during the Cisco integration period. Rival vendors frequently exploit acquisition integration timelines to aggressively poach enterprise accounts.
Public market valuations for pure-play observability vendors validate this consolidation demand. Datadog reported fourth-quarter 2024 revenue expectations between $709 million and $713 million, representing a 20% to 21% year-over-year growth rate [6]. The company maintained a 31% free cash flow margin while expanding its product footprint [3]. Financial performance at this scale requires displacing legacy incumbents.
Datadog leadership highlighted a specific transaction where a corporate client moved thousands of hosts to the cloud while eliminating two legacy infrastructure monitoring tools. This singular consolidation effort generated over $1 million in annual licensing savings and an estimated $10 million in productivity gains by reducing incident disruptions [7]. Another major European airline replaced dozens of homegrown commercial tools by adopting Datadog network monitoring alongside cloud security modules [6].

Gartner calculated the average cost of corporate network downtime at $5,600 per minute, which equals $336,000 per hour across all industries [8]. The Information Technology Intelligence Consulting 2024 survey corroborated these steep financial penalties, revealing that 91% of mid-sized enterprises incur hourly downtime costs exceeding $300,000 [9]. Small businesses lack the redundant systems maintained by large enterprises. Datto research reported an average hourly downtime cost of $8,000 for small and medium businesses [8]. Unplanned outages immediately stall revenue generation, interrupt automated supply chains, and inflict long-term reputational damage.
The Uptime Institute tracked these disruption triggers extensively in its 2025 Annual Outage Analysis. IT and networking configuration issues caused 23% of all impactful data center outages in 2024 [10]. While the overall global frequency of severe outages declined relative to digital infrastructure growth, the financial severity of individual incidents escalated. More than half of surveyed operators reported their most recent serious outage cost upwards of $100,000, and 20% reported financial damages exceeding $1 million [10].
Operator mistakes compound hardware vulnerabilities. The Uptime Institute noted a distinct spike in procedural failures, with human error related to ignored protocols rising 10 percentage points between 2024 and 2025 [11]. Nearly 40% of organizations suffered a major outage linked directly to human error over the past three years. Manual updates to complex routing tables frequently trigger cascading availability failures across distributed servers.
Enterprise buyers express mounting frustration with pricing models based on data ingestion volume. As multi-cloud architectures generate exponential telemetry data, ingest-based billing scales aggressively. Gartner actively warns that improving capability depth leads directly to rising software costs and extreme platform complexity [1]. Procurement officers face strict cost-fatigue, forcing vendors to introduce detailed data throttling controls.
The OpenTelemetry standard emerged as an independent framework to decouple data collection from proprietary vendor storage. IDC highlighted open standards and interoperability as a primary evaluation criterion in its 2025 MarketScape for Worldwide Observability Platforms [12]. Vendors must support OpenTelemetry to process federated data natively. Chronosphere entered the 2024 Gartner Magic Quadrant as a new market leader specifically by prioritizing open-source data compatibility and strict cost-control routing features [13]. Dynatrace retains the dominant incumbent position, but aggressive newer entrants force established vendors to abandon proprietary data collection agents [14].
Incumbents adapted quickly to the open-source threat. Datadog announced the embedment of a fully configurable OpenTelemetry collector directly within the Datadog agent during a 2024 earnings call [15]. This technical pivot grants enterprise customers seamless access to universal service monitoring without rewriting their baseline application code. Engineering departments refuse to deploy a separate monitoring agent for every distinct software vendor.
Cost control dictates procurement cycles for early-stage tech ventures optimizing infrastructure spend. These engineering teams operate with strict capital constraints and rely heavily on auto-scaling cloud services. Vendor platforms that ingest unmetered telemetry quickly exhaust startup operational budgets. Startups favor monitoring tools that aggregate logs selectively rather than storing complete packet capture data indefinitely.
High multi-tenancy environments demand relentless uptime metrics. For cloud software providers maintaining strict service agreements, latency spikes instantly trigger financial penalties. These organizations deploy distributed tracing solutions to map request paths across microservices. When a database query blocks an external API response, the monitoring platform must isolate the failing container before global traffic routing degrades.
Corporate acquisitions mandate rapid IT infrastructure audits. As investment groups managing portfolio network integrations consolidate acquired subsidiaries, they inherit conflicting domain controllers and legacy firewalls. Private equity IT directors utilize discovery tools to automatically map physical server dependencies. Network visualization accelerates the deprecation of redundant hardware during the critical first year of an acquisition.
Geographic dispersion introduces severe hardware latency. Remote site management challenges commercial builders establishing temporary site connectivity on active construction zones. These networks rely on cellular modems and secure SD-WAN connections rather than stable fiber lines. Network performance tools in this sector focus heavily on connection persistence and packet loss monitoring across unpredictable wireless environments.
Employment data illustrates a structural change in how companies manage server hardware. The Bureau of Labor Statistics projects a 2.6% employment decline for network and computer systems administrators between 2023 and 2033, shedding 8,800 jobs [16]. Companies no longer require vast teams of administrators to manually configure local routers. Conversely, the Bureau projects a 12% employment growth for computer network architects over the same decade [17]. Strategic design overtakes manual maintenance as the primary engineering requirement.
Artificial intelligence algorithms absorb the routine configuration tasks previously handled by sysadmins. Forrester ranked AI agents as the foremost emerging technology trend for 2024, emphasizing their capacity to autonomously orchestrate software deployments [18]. New Relic integrated specialized large language models to provide cross-platform automation [1]. Instead of writing custom SQL queries to parse server logs, engineers prompt the AI interface in plain text to locate traffic bottlenecks.
Gartner anticipates that 30% of enterprises will automate more than half of their network activities by 2026, a sharp increase from under 10% in mid-2023 [9]. Machine learning modules suppress false positive alerts, preventing alert fatigue among security operations center personnel. Automation frameworks detect irregular traffic volumes, isolate the affected subnet, and reroute traffic without human intervention.
Telecommunications operators use these predictive models to dictate capital expenditures. Global mobile operator capital expenses will decline at a 2.5% compound annual growth rate through 2030 [19]. Telecom companies deploy AI data twins to simulate how new cell sites or spectrum upgrades will alter customer network speeds. This simulated network modeling guarantees accurate return on investment calculations prior to breaking ground on physical infrastructure.
Security operations and network performance management overlap completely in modern enterprise architectures. IBM calculated the average cost of a data breach at $4.88 million in 2024 [8]. Hackers use encrypted network traffic to exfiltrate database records silently. Threat containment requires an average of 258 days. Without deep packet inspection and baseline traffic mapping, security analysts cannot identify lateral threat movement across an internal corporate network.
Forrester identified the Zero Trust Edge as a persistent trend, combining networking and security tools into a unified cloud service [18]. The principle dictates that no network request receives implicit trust, regardless of geographic origin. Network monitoring platforms enforce these strict security and compliance programs by logging every internal authorization attempt. Observability vendors actively acquire security firms to provide native application vulnerability blocking directly within the monitoring agent.
Market pressures force traditional performance monitoring companies to evolve into predictive intelligence platforms. The aggregation of traces, metrics, and application logs provides the exact training data required for autonomous system remediation. As data ingestion costs force enterprises to standardize on open-source collection protocols, vendor differentiation shifts entirely to analytical capability.
Gartner research confirms that 75% of enterprises currently seek automation solutions compatible with hybrid and multi-cloud environments [2]. The next iteration of network architecture relies on declarative intent. Engineers will define the required application response time, and the underlying software-defined network will dynamically allocate bandwidth to meet that parameter. Administrators will function exclusively as strategic auditors, evaluating machine-generated network modifications rather than provisioning individual server connections.
| Year | Adoption Rate (%) |
|---|---|
| 2021 | 15 |
| 2022 | 22 |
| 2023 | 30 |
| 2024 | 42 |
| 2025 | 54 |
The provided data reveals a dramatic acceleration in the enterprise adoption of AI-powered monitoring, escalating from an estimated 15 percent in 2021 to 54 percent by the end of 2025 [1]. This operational shift perfectly mirrors the financial trajectory of the global Artificial Intelligence for IT Operations (AIOps) market, which expanded from approximately 11.5 billion dollars to nearly 19 billion dollars over the same five-year period [2]. What this demonstrates is a decisive industry-wide migration away from fragmented, rule-based alerting systems toward unified, machine-learning-driven observability platforms capable of processing massive volumes of telemetry data in real-time [3].
At a micro level, this transition means that IT and network operations teams are actively consolidating their monitoring tool stacks, significantly reducing the average number of specialized tools per organization from six to around four [4]. Instead of siloing network performance metrics away from application health, engineers are leveraging a great convergence where end-user experience serves as the primary metric and network infrastructure provides the diagnostic context [5]. On a macro industry scale, vendors are aggressively pivoting their portfolios to offer experience intelligence and predictive remediation, with major players acquiring observability startups to build full-stack, end-to-end resilience ecosystems [6]. Furthermore, managed service providers are capitalizing on this trend by bundling AIOps into consumption-based subscriptions, effectively lowering the adoption friction for small and medium-sized enterprises that lack dedicated, round-the-clock site reliability engineering teams [1]. Ultimately, this signifies that traditional network monitoring is evolving into agentic AI execution, where probabilistic machine learning models not only detect anomalies but autonomously reroute traffic and execute self-healing scripts without human intervention.
The financial and operational stakes of maintaining network uptime have never been higher, with network downtime now costing enterprises an average of 5,600 dollars per minute, translating to over 300,000 dollars per hour [7]. Compounding this risk is a severe global workforce crisis; as of 2024, the cybersecurity and IT operations sector faces a staggering shortage of 3.5 million unfilled positions, leaving existing security teams dangerously understaffed and highly susceptible to burnout [8]. Implementing a formal observability and AIOps strategy is vitally important because it directly offsets this human capital deficit by filtering out alert noise, correlating events across complex hybrid architectures, and reducing incident resolution times by up to 50 percent, allowing constrained IT teams to focus on strategic innovation [9].
The exponential proliferation of microservices and cloud-native architectures has generated tenfold more telemetry data than legacy monolithic stacks, fundamentally overwhelming traditional, static threshold-based monitoring tools [3]. Simultaneously, the rapid expansion of edge computing, 5G rollouts, and multi-cloud environments has dissolved the traditional enterprise network perimeter, meaning the vast majority of enterprise traffic now traverses public networks and third-party infrastructures that the enterprise does not directly own [5]. I speculate that the breaking point occurred when alert fatigue reached critical mass; legacy tools produced so many false positive alarms that desensitized on-call engineers began missing genuine, user-impacting incidents. High-profile, costly network outages and increasingly stringent regulatory mandates regarding critical infrastructure visibility likely served as the final catalysts, forcing C-suite executives to aggressively authorize budgets for AI-driven platforms that promise guaranteed service consistency and continuous threat exposure management [10].
The era of fragmented, human-dependent network monitoring is effectively over, rapidly being replaced by an era of autonomous, AI-driven observability that links underlying infrastructure health directly to end-user experience. As digital ecosystems continue to expand in complexity and the global IT skills shortage persists, relying on reactive troubleshooting is a guaranteed path toward catastrophic financial losses and reputational damage. The prominent takeaway for IT and business leaders is that investing in AIOps and unified network observability is no longer merely an operational upgrade, but a foundational requirement for digital resilience and competitive survival in a hybrid-first world.